
GoogleAnalyticsでサイトのアクセス解析なんかをしてる人は個人・企業問わず多いかと思います。
基礎的なデータなら勝手にサマリーで出してくれますし、ゴールを上手く設定すればアトリビューション分析も可能です。
ただ、分析をしたいと思っている人が思うことは恐らく一緒のはずです。
「見栄えの良いグラフとかいいからとりあえず生のデータを見せろ」
はい、ごもっともですw
別にこれはアナリティクスだけに限った話ではなくて、研究で色々な資料を読んでる時とかにもありますよね。このグラフの作成元のデータを分析してなにか面白い事を見つけたいのに、問い合わせても手に入るのはグラフのみ。
幸いなことにGA(google analyticsの業界人の略らしいw)ではAPIを使ってこのデータを入手することが可能です。サクッと検索したらPHPとかで呼び出す方法もありましたが、Rのパッケージで入手する方法もあったので当然Rで呼び出しましょう〜。(ちなみにRとはオープンソースの統計分析ソフトです。)
ちなみに調べたらSAS,SPSS,STATAでもアクセス可能に成る方法が乗ってたのでRなんて貧乏人のソフト使ってられるかって人はぐぐってみてください。
さて、導入方法なわけですが。
https://code.google.com/p/r-google-analytics/
英語が堪能な人は上のサイトを参照すれば良いかと思います。
とりあえず必要なパッケージをインストールしましょう
install.packages(“RCurl”)
install.packages(“rjson”)
上のサイトだとRJSONと大文字になっていてパッケージが見つからないので小文字に修正。
RGoogleAnalytics packageはinstallコマンドからなぜかインストール出来なかったので、上のサイトの左側にあるダウンロードからパッケージをダウンロードして、ファイル指定でインストール。
GAにログインした状態で下のコマンドを実行。
require(“RGoogleAnalytics”)
query <- QueryBuilder()
access_token <- query$authorize()
するとOAuth2.0のアクセス許可をブラウザ上で求められるのでallowして、send a request.
したらアクセストークンが右下の方に表示されるのでそれをコピー。
Rに戻るとアクセストークンの入力が求められているのでペーストして実行。
ga <- RGoogleAnalytics()
ga.profiles <- ga$GetProfileData(access_token)
ga.profiles
クエリーの定義(どんなデータを要請するかを定義してます)。膨大なデータを要請するのでなければ片っ端からデータ取得して後から加工したほうがいいのかもしれないと思います。
query$Init(start.date = “2013-04-05”,
end.date = “2013-05-05”,
dimensions = “ga:date,ga:pagePath”,
metrics = “ga:visits,ga:pageviews,ga:timeOnPage”,
sort = “ga:visits”,
#filters=””,
#segment=””,
max.results = ,
table.id = paste(“ga:”,ga.profiles$id[1],sep=””,collapse=”,”),
access_token=access_token)
GAから上で定義したデータを要請して、ga.dataという変数に入れてます。後は普通のRと同じように分析が可能になります。
ga.data <- ga$GetReportData(query)
まだ1時間ほどしかいじってないのですが、気がついた点が何点か。
データ加工が結構しんどいw
外れ値をデータセットから抜いてゆかないといけないわけですが、外れ値の定義とかも結構あやふやですよね。
例えば滞在時間が5万秒(13時間)とかはあからさまに変だから外せるのだけれど、1時間とかだと結構悩む。
この辺りをちゃんと定義するにはwebページをみんながどんな感じで巡回してるかっていう部分に関する明確なアイデアが無いと痛い目見そう。
とりあえず外れ値探しをするためにプロットしてみる。(summaryでもいいかもしれない)
plot(ga.data$timeOnPage)
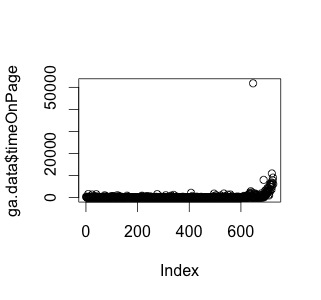
あからさまにおかしい値があるのでそれを除外。
しかし、ここで考える。そもそも20000秒も長いんじゃないかと。
ということでひとまず30分を上限値にしてデータを切ってみる。
dai = subset(ga.data, timeOnPage < 1800 & timeOnPage > 1)
観閲時間が0なものもデータから除外。
で、とりあえずヒストグラムを作る。
hist(dai$timeOnPage, breaks = “Scott”)
Scottは別に適当に数字を振ってもいいです。その場合はヒストグラムの棒の本数を指定する結果に成ります。breaks=10 で棒が10本のヒストグラムが出来上がります。
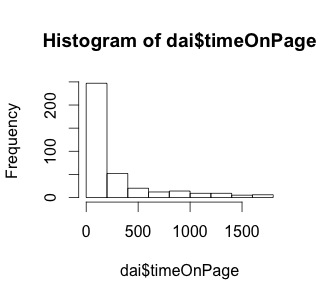
多分ブログの記事を読む時間なんて2分程度なので結構妥当な結果何じゃないでしょうか?
で、今度はページビューと滞在時間をプロットしてみる。
plot(dai$timeOnPage, dai$pageviews)
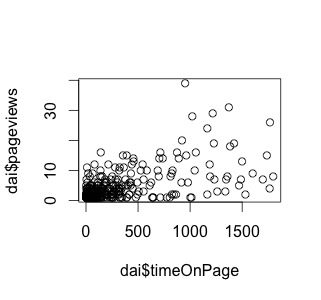
どーだろ?
なんとなーく相関が見える気がしなくも・・・
あとheteroschedasticityも見えますね。
とりあえず一発回帰分析してみましょう。
summary( lm(pageviews ~ timeOnPage, data = dai) )
Coefficients: Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.0215058 0.2534727 7.975 1.89e-14 ***
timeOnPage 0.0076399 0.0005406 14.133 < 2e-16 ***
— Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.05 on 372 degrees of freedom Multiple R-squared: 0.3494, Adjusted R-squared: 0.3476
F-statistic: 199.7 on 1 and 372 DF,
p-value: < 2.2e-16
とりあえず優位な結果が出ました。
滞在時間が長くなるような記事を書けばその記事のPVは上がりますよん。って事ですかね。
「滞在時間=読むのにかかる時間」と捉えれば、気合入れて書いた記事はPV稼げるとも考えられなくもないです。が、一方で内容の増加から起きる単語数の増加で検索に引っかかりやすくなったとかただそれだけな気がしなくも無いです。
記事ごとの字数とトラフィックのデータも導入出来ればそのへんは解りそうですね。
とまぁ、「導入〜データの取得〜簡単な分析」とやってみました。
分析部分は特に仮説なく分析をぶつけただけなのでろくな物では無いですが、お役に立て・・・てるといいです。
もしくは「あ〜こういうこと出来るのね〜」くらいに思っていただければ良いです。
あ、で、終わった後に気がついたんですが・・・
ろくにデータの定義を理解しないままにやってましたw
色々データの定義を探して回ったんですが結局グーグルの公式が一番詳しいっぽいですね。↓
https://developers.google.com/analytics/resources/concepts/gaConceptsDataCalculation?hl=ja-JP#dimensionsAndMetrics
ちゃんと読んだら定義の解説記事でも書きます。