
最近何も書かないですねーとよく言われる今日この頃なので書きます。
あ、別になんかスゲー事書くわけではないっす。
ちょっと正則化のLassoとRidgeの解釈的な部分について書きます。
一応回帰前提です。

正則化ってなんすか?
過学習を防ぐためのテクニック、若しくは変数選択の一種です。ほかにもいっぱい言い方ある気がしますが。
モデルに1000個の変数を入れて学習したとき、1000個のパラメータがコスト関数の最小化の解として得られます。
この時パラメーターの数が多すぎると、それを微妙に調整することでたまたま現れてしまうような再現性の無いパターンを学習できるような状況になってしまい、結果予測精度が落ちるという過学習の問題が発生します。
で、これを避けるために使うのが正則化です。
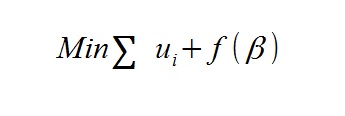
すごい雑な式を入れると、上のようなコスト関数の最小化をβに関して解くことですね。
u_iは各観測における誤差の二乗を表しています。(画像作るときにu^2にし忘れた・・・)
普通のモデルであれば、二乗誤差を最小化するのみになります。
が、正則化を用いると一緒にこのf(β)も最小化しなくてはなりません。
つまり、このf(β)を一緒に最小化する事でモデルが何かしらの恩恵を受けて過学習をしなくて済むわけですね。
f(β)は様々な形をとることができますが、一般的に用いられるのは
Lasso: f(β) = λ* |β|
Ridge: f(β) = λ*0.5*β^2
の二つかと思います。
どちらも意味合い的には同じで、「誤差と一緒にパラメーターの絶対値も最小化しちゃえ」というものですね。
λの大きさによって、パラメーターをより小さくするほうがコスト関数を小さくするうえで効率的になるか、それとも二乗誤差を小さくするほうが効率的かが違ってきます。
パラメーターの絶対値を小さくすると何故過学習を防げるのか?についてはちょっと今の僕は力不足な感じですがあえてなんか説明を出すとしたらですね。。。
パラメーターの値が0から学習していったらパラメーターはモデルが経験を積むごとに絶対値が少しずつ増えていくので、パラメータの絶対値の最小化はその学習に適度な上限をもたらす事になるのかなと。
感覚的にはこんな感じな気がしています。はい、忘れてくださいw
RidgeとLassoではコスト関数の最小化におけるパラメーターの値を変える意味合いが多少違って来ます。
Ridgeの場合パラメーターの二乗の値がコスト関数に入っているので、より大きいパラメーターを1小さくする方が小さいパラメーターを1小さくするよりもコスト関数がより小さくなることになります。
よって最小化の過程であるパラメーターを小さくしていったときに一定以上小さくするよりも、別のもっと大きい値を持っているパラメータを小さくする方がコスト関数がより小さくなるという点が必ず訪れます。
なので、Ridgeの場合にはパラメータが0になりにくいという特性が生まれます。
Lassoの場合はパラメータの絶対値がコスト関数に入っているので、パラメータの大きさがパラメーターの変化がコスト関数に与える影響を左右する事はありません。
なので、コスト関数の最小化においてパラメーターの絶対値は0に容易に達することができます。
LassoとRidgeの説明が出てくると下のようなグラフがよく出てきます。
パラメーターの値をとりうる領域を示すグラフなんですが、ちょっとわかりにくいなーって前から思ってます。(僕の数学力不足が原因かもしれないですが・・・)
それが言いたかっただけですw
さて、機械学習やるといろいろなところに正則化が出てきて面白いです。
ニューラルネットでデータの入力の回転等に対応するために、回転によって発生する誤差を関数化してコスト関数に突っ込んでしまう正則かなんかも凄い発想だなと素直に驚くわけです。
そしてすごい自由である事にも驚くわけです。
なんか自由な発想して、消し込みたいモデルの要素をコスト関数に入れて最小化出来ないもんかな。
それこそバイアスとか。