
最近位置情報のデータを仕事でもプライベートでも扱ってます。
そんな中国土交通省の「国土数値情報 ダウンロードサービス」から落とせるデータの扱いで色々困ったのでまとめておきます。

さて、上記のサイトでは基本的にダウンロードできるデータがshape fileになっています。
csvにまとまっているものも存在するのですが、すべてのデータがcsvになっているわけではないのでshapeを扱えないと困ってしまう可能性があります。
1. shape fileからのデータの読み込み
色々調べましたが、基本的にはmaptoolsパッケージのreadShapeXXXXを使うのが良さそうです。XXXXにはshapeファイルの中に入っているデータの種類で違います。
ポリゴンデータならPolyが入るといった具合です。
Lines, Poly, Points, Spatialの4種類があります。Spatialだけ勉強不足でちゃんとわからないのですが、その他3種類はそれぞれ地形の特徴を表す表現の方法なので、Spatialもきっとそうなのだろうと考えています。
Linesは線の形をした特徴で、道路や鉄道といった交通網がそれにあたるかと思います。
Polyは面の形をした特徴で、地域の区分や等高線なんかもこれに入ります。
Pointsは点の特徴で、施設なんかがこれにあたるかと思います。
※間違ってたり補足あればご指摘ください。
例えばこちらの日本の行政区画を読み込みたければ以下のようにすれば良い訳です。
#map of japan
jap <- readShapePoly(“japan_ver72.shp”)
plot(jap)
するとプロットの結果はこんな感じです。
いったん読み込んだ後の話とか、何に使うのかとかは置いておいて、読み込みは出来ました。
2. メタデータからのデータの読み込み
次に施設の位置等の点のデータを読み込みます。
国土数値情報 ダウンロードサービスからデータを落としてくると、XML形式のメタデータが付いてきます。
普段スクレイピングをする身からすると、XMLのデータの方がずっと扱いやすいので、素直に(?)こっちからデータを持ってきます。
東京都の学校の緯度経度のデータを取り出してみます。
#school
doc <- xmlParse(“data/P29-13_13/P29-13_13.xml”)
latlon <- xpathSApply(doc, “//gml:Point”,xmlValue) %>%
strsplit(” “) %>%
unlist() %>%
matrix(ncol = 2, byrow = T)
lat <- latlon[,1] %>% as.numeric()
lon <- latlon[,2] %>% as.numeric()
name <- xpathSApply(doc, “//ksj:name”,xmlValue)
type <- xpathSApply(doc, “//ksj:type”,xmlValue)
school <- data.frame(name, lat, lon, type)
> head(school)
name lat lon type
1 お茶の水小学校 35.69735 139.7604 16001
2 暁星小学校 35.69868 139.7484 16001
3 九段小学校 35.69029 139.7405 16001
4 麹町小学校 35.68553 139.7398 16001
5 昌平小学校 35.70115 139.7699 16001
6 千代田小学校 35.69349 139.7685 16001
とまぁ、施設の緯度経度のデータも取り出せました。
Rに読み込みさえすればあとは何とかデータフレームに変換していろいろ集計出来そうです。
プロットとかもGoogleVis使ったり、leaflet使ったりすればどーにか出来そうです。(@yamanoさんいろいろ情報ありがとうございます)
もうこれで良いかな?とか思ったんですが、ただまぁそうは問屋が卸さない場合もあるわけです。
3. ある場所がどのエリアに入っているかを判別したい。
これです。
一番やりたかったのはこれなんです。
ある緯度と経度が与えられた時に、その場所ってどんな特徴を持ってるんだっけ?というのが超知りたいわけです。
例えば下の様なデータがあるとします。
A,BはreadShapePolyで読み込んだポリゴンデータで、
1,2,3,4はメタデータから読み込んだ学校の位置のデータです。
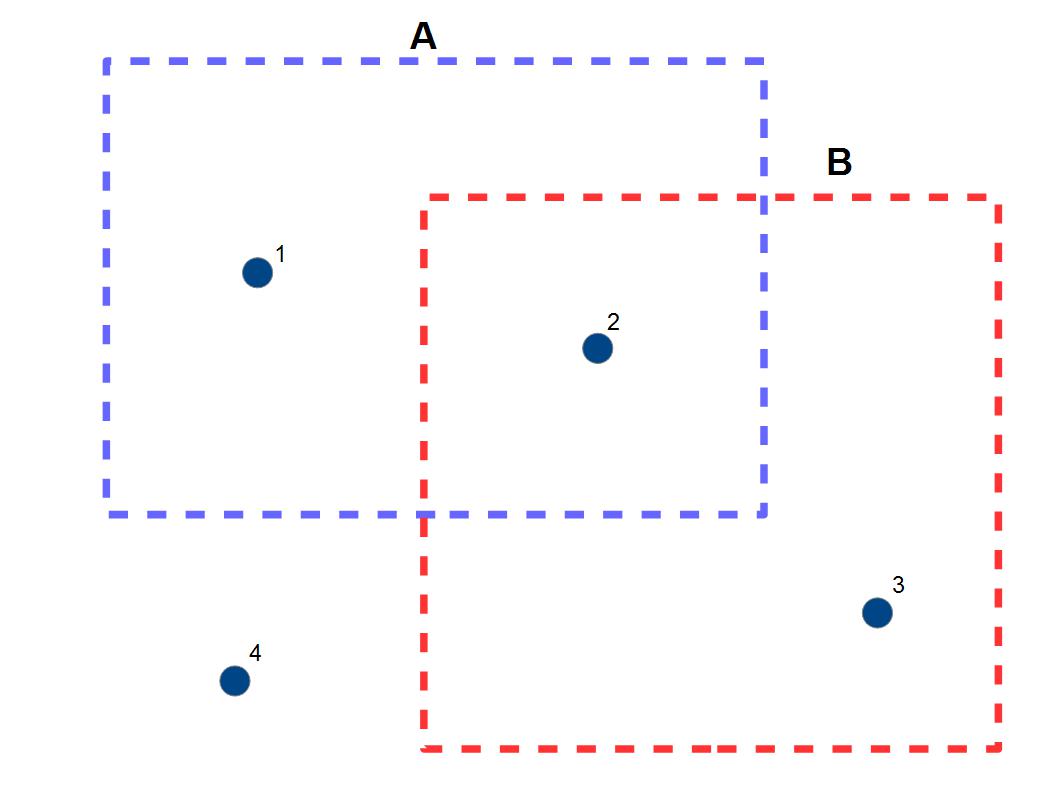
それぞれの学校はどのような地域的な特徴を持っているのかをデータとして持ちたいとします。
つまり、学校の緯度経度のデータフレームの右にA・B・A&B・なしが入るカラムを付け加えたいわけです。
ちなみに上のデータだと、1がAの中にあり、2がAとBの中にあり、3がBの中にあり、4がどちらの中にもない状態で、これをRで判別したいというわけです。
さくっと探すとmongoDBにgeoIntersectsなる機能があることが見つかりました。
が、僕はRでやりたいわけです。
そして色々探している間にspパッケージという湿気た名前のパッケージを見つけます。
とりあえずリファレンスのpdfを開いてそれっぽい言葉で検索するとoverという関数があるらしく、どうやらやりたいことが出来そうな感じがします。
で、下みたいな感じで書くと出来ました。
#1で読み込んだ日本の地域をspパッケージのポリゴンデータとして扱う
japan <- SpatialPolygons(jap@polygons)
#学校の点データをspパッケージのポイントデータとして扱う
x <- school[,2]
y <- school[,1]
xy <- cbind(x,y)
dimnames(xy)[[1]] <- c(1:NROW(school))
pts <- SpatialPoints(xy)
#ポリゴンデータとの重ね合わせ
ov <- over(pts,japan, returnList = FALSE)
schoolov <- data.frame(school,areaid = ov)
areadata <- data.frame(areaid = 1:length(japan), jap@data$SIKUCHOSON)
schoolov <- schoolov %>% left_join(areadata,by=”areaid”)
> head(schoolov)
lat lon shisetu areaid jap.data.SIKUCHOSON
1 35.69735 139.7604 小学校 662 千代田区
2 35.69868 139.7484 小学校 662 千代田区
3 35.69029 139.7405 小学校 662 千代田区
4 35.68553 139.7398 小学校 662 千代田区
5 35.70115 139.7699 小学校 662 千代田区
6 35.69349 139.7685 小学校 662 千代田区
over(x,y)という関数なんですが、
xに点データを入れてyに面のデータを入れると、点がどの面に属するか?という値をすべての点において返してくれます。
xに面データを入れてyに点データを入れると、面にどの点が属しているか?という値をすべての面において返してくれます。
ということで、これで色々な面のデータを貯めてゆけば、どの地点がどんな特徴を持っているか?というデータを出すことが出来るようになるわけです。
めでたしめでたし。
4.余談
この最後のSPパッケージなんですが、作成者のうちの一人であるRoger Bivand が大学院での先生でした。
確かに今思うと僕に一番最初にRを使う様に促したのもこの方でした。(ガン無視しましたがw)
決して順序は逆にはならないんだけれども、Rの事を良く学んでから大学院に行っていたらまた違った世界を見て、違った選択をしていたのかな?と思いました。
もう少しモデリングチックな事をする段階になったら、Rを使う様になった事を添えて連絡をしてみようかな。
ピンバック: rChartsからleafletを使って地図を書いてみた。 | 分析のおはなし。